
Improving the Reusability of Research Software through Standardized Data Formats and Tool Interfaces
Challenge
In many fields, research involves the implementation of prototypal software tools. These tools are evaluated for correctness and efficiency by applying the to benchmarks, i.e. collections of problems with relevant metadata. In Software Engineering, a correctness checker for programs might be evaluated against a benchmark containing programs, formalized correctness properties and true-false-information. The more properties a tool can refute or prove correctly, the better it is. Reproducibility of experimental results is guaranteed – especially in Software Engineering – by artifacts that accompany scientific publications. A benchmark packages tools, benchmarks and execution scripts in a container (e.g., a virtual machine) and is usually archived on a platform like Zenodo.
To enable subsequent research projects, it is desirable to execute “historic” tools on new benchmarks as well as evaluate new tools on exiwsting benchmark suites. This would show both the evolution of tools as well as improve the quality of evaluation due to growing benchmarks sets the ability to perform direct comparisons against competing tools.
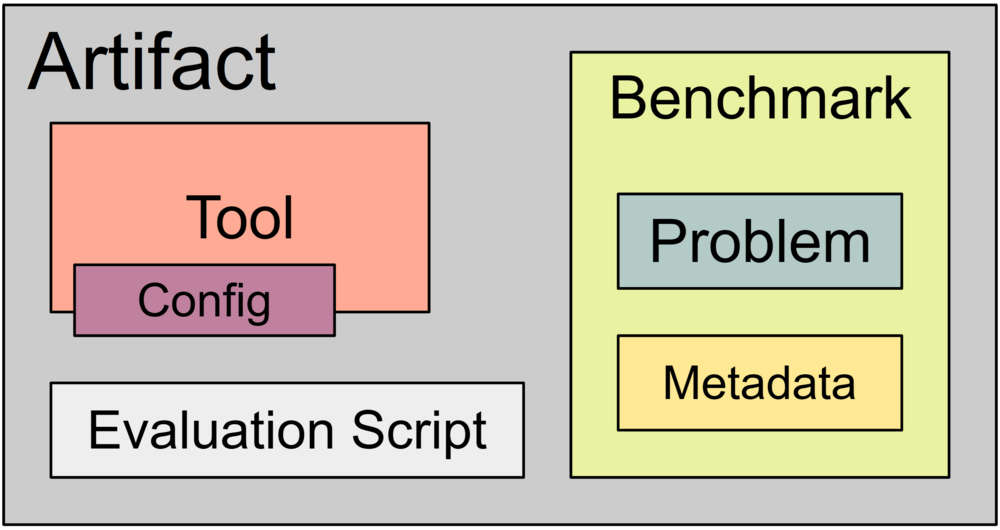
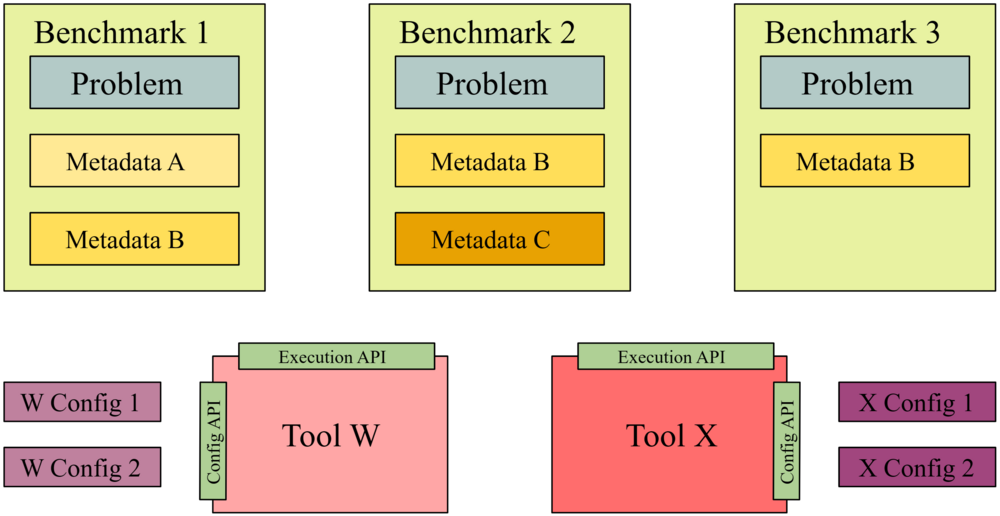
To enable such resue, we require archival formats for both tools and benchmarks that enables arbitratry combinations of both by mean of long-term usable interfaces. (In the ISSTA 2014 Artifact Evaluation Committee, we proposed the name “buildability” for this property, however, it has not yet been formalized.) This project aims to work towards such standards by proposing both interdisciplinary baseline standards for
- tool packaging,
- tool execution,
- tool configuration,
- problem packaging, and
- problem metadata.
These will be combined with concrete, community-specific standards for specific types of configuration and metadata that will build on the baseline standard in a bottom-up mode. We plan to propose formats for three domains:
- security analyses with a focus on taint analysis,
- register automata analyses, and
- autonomous driving with a focus on traffic scenarios and track definitions.
Funding
The project is supported by a NFDI4Ing Seed Fund.
 © NFDI4Ing
© NFDI4Ing